Building a Conversational Chatbot with Memory for your PDFs
- Nov 16, 2023
- 6 min read
Updated: Dec 1, 2023

Motivation
With the rise of Generative AI and Large Language Models, creating a chatbot to interact with your own private documents has never been easier.
This article will show you the process of building a simple chatbot that can interact with your PDFs and is able to maintain back-and-forth conversation using chat history stored in memory.
Here is how the final app will look like!
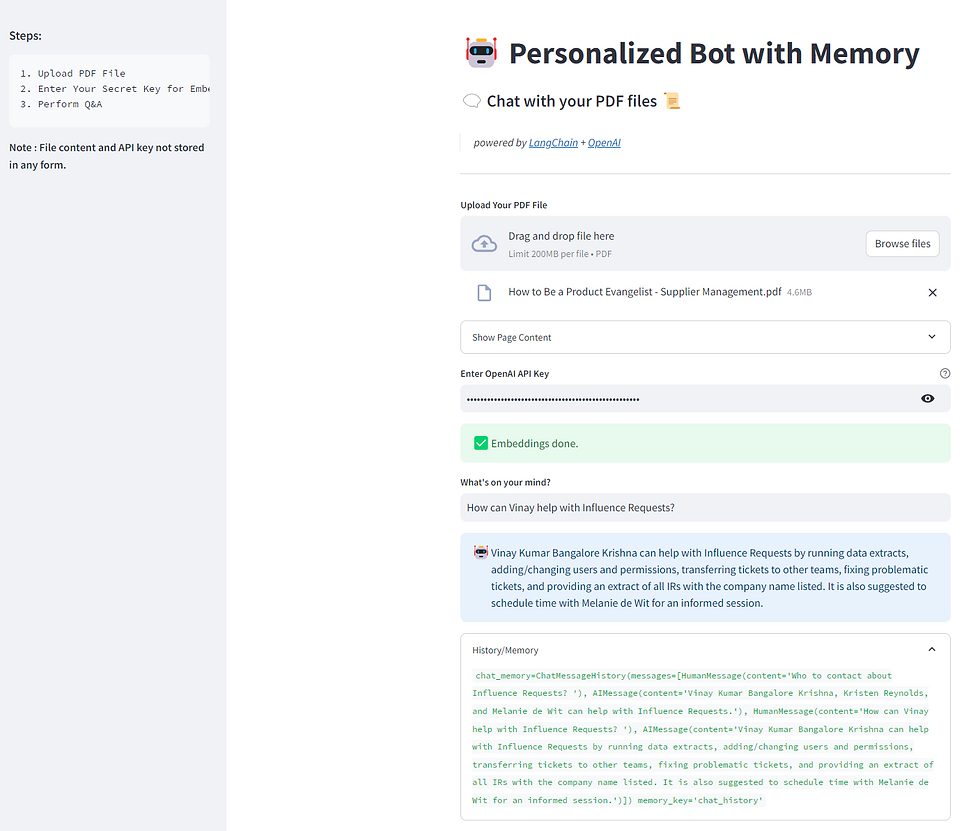
Below is a demo video to show the app works!
Project Overview
Built a conversational chatbot for PDFs using OpenAI API and LangChain, with embedded memory to maintain conversation with human users
Deployed LangChain's ConversationalBufferMemory module to store past exchanges in context
Utilized OpenAI Embeddings to generate text embeddings from PDFs
Utilized FAISS vector store to store embeddings for index retrieval
Designed user interface and deployed chatbot using Streamlit
Resources and Tools
Language: Python
Packages: openai, langchain, streamlit, pypdf
Table of Contents:
a. OpenAI API & LangChain
b. Embeddings & Vector Stores
c. Adding Memory
a. Processing PDFs
b. UI Setup
I. How does this work?
Before we jump into building the chatbot, let's try to understand the innerworkings behind how a chatbot operates and what resources needed to build one.
a. OpenAI API & LangChain
*What is OpenAI API & Why do we need it?
OpenAI is the company behind ChatGPT - the chatbot that has been taking the world by storms. OpenAI provides an API (or Application Programming Interface) that allows developers to integrate and use OpenAI's large language models, like GPT-3.5 or GPT-4, in their applications.
Developers can make API requests using an API secret key that can be found on this platform.
For this project, we will use the OpenAI Python library ("openai") to use the GPT-3.5 Turbo model as our large language model.
In addition, we will also generate embeddings (concept explained below) from our PDFs using OpenAIEmbeddings.
*What is LangChain & Why do we need it?
LangChain is an open-source framework for developing applications powered by language models.
Specifically, LangChain offers an useful approach of preprocessing text by breaking it down into chunks, embedding them in a vector space, and searching for similar chunks when a question is asked.
In this project, the langchain Python library provides many functions that correspond with each step in the text preprocessing workflow:
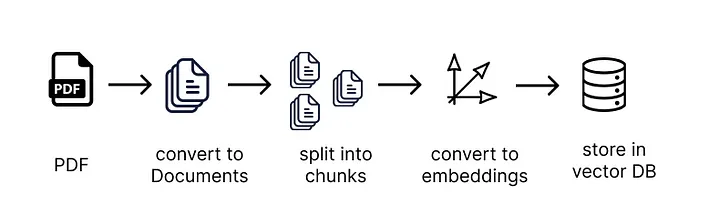
1. Load PDFs and convert them into "Documents" - one Document for each page of the PDF
2. Split the document into small chunks of text
3. Pass each chunk of text into an embedding transformer to turn it into an embedding
4. Store the embeddings and related pieces of text in a vector store
b. Embeddings & Vector Stores
So what are embeddings and vector stores?
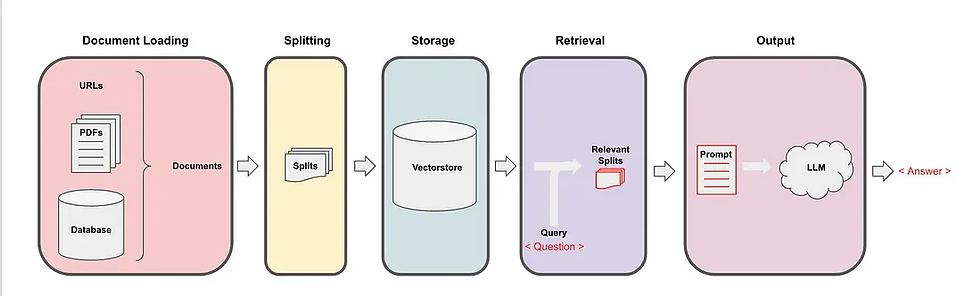
We need to know that an LLM has a size (token) limit when it comes to requests. This means that, with large sized documents, we can only send relevant information from the documents to the LLM prompt. But how do we get relevant information from the documents in an efficient way?
Embeddings and vector stores can help us with this.
An embedding allows us to organize and categorize a text based on its semantic meaning. So we split our documents into lots of little text chunks and use embeddings to characterize each bit of text by its semantic meaning. An embedding transformer is used to convert a bit of text into an embedding.
An embedding categorizes a piece of text by giving it a vector (coordinate) representation. That means that vectors (coordinates) that are close to each other represent pieces of information that have a similar meaning to each other. The embedding vectors are stored inside a vector store, along with the chunks of text corresponding to each embedding.
In our case, we will be using the OpenAI embeddings transformer, which employs the cosine similarity method to calculate the similarity between documents and a question.
c. Adding Memory
We can add memory to the chatbot using ConversationBufferMemory - a simple form of memory offered by LangChain to keep a list of chat messages in a buffer and passes those into the prompt template. For more information on memory, take a look at this documentation.
II. App Building
With the concepts cleared, let's start building our chatbot.
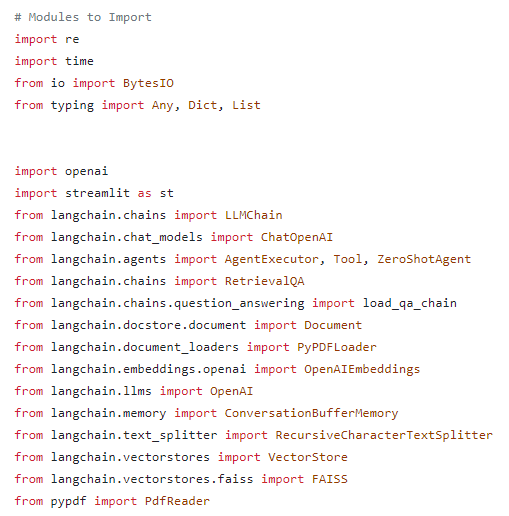
First, we will load the necessary libraries:
Next, we will need to define local functions to process our uploaded PDFs.
a. Processing PDFs
In order to properly process the PDFs, we need our function to be able to do the following:
1. Load PDFs and convert them into "Documents" - one Document for each page of the PDF
2. Split the document into small chunks of text
3. Pass each chunk of text into an embedding transformer to turn it into an embedding
4. Store the embeddings and related pieces of text in a vector store
We will define three functions to do the following:
1. The parse_pdf() function takes a PDF file object, extracts its text, and cleans it up by merging hyphenated words, fixing newlines in the middle of sentences, and removing multiple newlines. The resulting text is returned as a list of strings, one for each page of the PDF.

2. The text_to_docs() function converts a list of strings (e.g., the output of parse_pdf()) to a list of LangChain Document objects. Each Document represents a chunk of text of up to 4000 characters (configurable). The Document objects also store metadata such as the page number and chunk number from which the text was extracted.

3. Function for embeddings: The test_embed() function uses the LangChain OpenAI embeddings by indexing the documents using the FAISS vector store. The resulting vector store is returned.
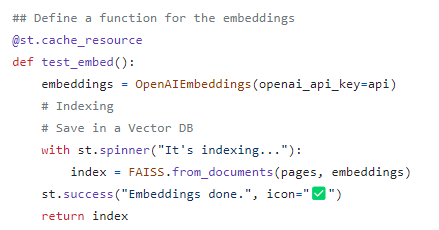
Detailed code can be found in this script.
b. UI Setup
First, we set the app title and add description to our chatbot.
st.title("🤖 Personalized Bot with Memory ")
st.markdown(
"""
#### 🗨️ Chat with your PDF files 📜
> *powered by [LangChain]('https://langchain.readthedocs.io/en/latest/modules/memory.html#memory') +
[OpenAI]('https://platform.openai.com/docs/models/gpt-3-5')*
----
"""
)
st.sidebar.markdown(
"""
### Steps:
1. Upload PDF File
2. Enter Your Secret Key for Embeddings
3. Perform Q&A
**Note : File content and API key not stored in any form.**
"""
)Load PDF files
Next, we will add a section to allow user to upload a PDF file using the file_uploader function that we've defined previously. It checks whether the file was uploaded and calls the parse_pdf function to extract the text from the file. If the PDF contains multiple pages, it prompts the user to select a page number.
# Allow the user to upload a PDF file
uploaded_file = st.file_uploader("**Upload Your PDF File**", type=["pdf"])
if uploaded_file:
name_of_file = uploaded_file.name
doc = parse_pdf(uploaded_file)
pages = text_to_docs(doc)
if pages:
# Allow the user to select a page and view its content
with st.expander("Show Page Content", expanded=False):
page_sel = st.number_input(
label="Select Page", min_value=1, max_value=len(pages), step=1
)
pages[page_sel - 1]Create Embeddings
Then, we ask the user to input their OpenAI API key using the text_input function, which is further used to create embeddings and index them using FAISS.
api = st.text_input(
"**Enter OpenAI API Key**",
type="password",
placeholder="sk-",
help="https://platform.openai.com/account/api-keys",
)
if api:
# Call test_embed() function and save the result in "index" variable
index = test_embed()
# Set up the question-answering system
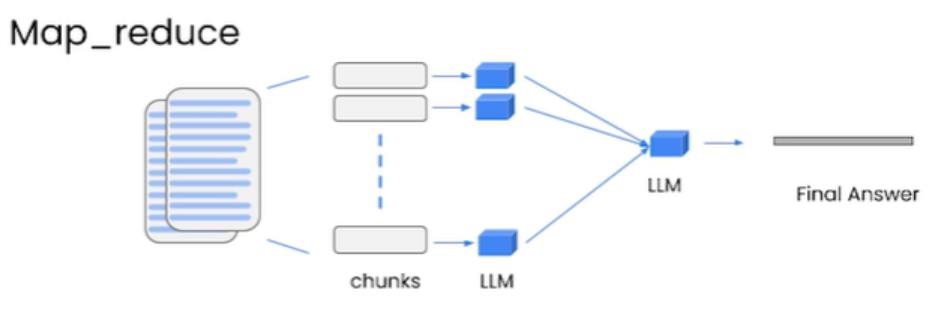
qa = RetrievalQA.from_chain_type(
llm=OpenAI(openai_api_key=api),
chain_type = "map_reduce",
retriever=index.as_retriever(),
)Implement RetrievalQA Chain
We then use the retrieval-based question-answering (QA) system using the RetrievalQA class from the LangChain library. It uses an OpenAI language model (LLM) to answer questions, with a chain type of “map_reduce”. The retriever is the vector database that we created previously.
Set up conversational agent using Tool
# Set up the conversational agent
tools = [
Tool(
name="Personalized QA Chat System",
func=qa.run,
description="Useful for when you need to answer questions about the aspects asked. Input may be a partial or fully formed question.",
)
]Create prompt using ZeroShotAgent class
prefix = """Have a conversation with a human, answering the following questions as best you can based on the context and memory available.
You have access to a single tool:"""
suffix = """Begin!"
{chat_history}
Question: {input}
{agent_scratchpad}"""
prompt = ZeroShotAgent.create_prompt(
tools,
prefix=prefix,
suffix=suffix,
input_variables=["input", "chat_history", "agent_scratchpad"],
)
Adding Memory
We will create a "memory" variable in the st.session_state dictionary using the ConversationBufferMemory class. This allows the chatbot to store previous conversation history to help inform future responses.
if "memory" not in st.session_state: #Create 'memory' variable to store chat history
st.session_state.memory = ConversationBufferMemory(
memory_key="chat_history"
)Create an LLMChain instance
The LLMChain class represents a chain of language models that can be used to generate text. In this case, the chain consists of a single language model, which is an instance of the OpenAI class.
llm_chain = LLMChain(
llm=ChatOpenAI(
temperature=0, openai_api_key=api, model_name="gpt-3.5-turbo"),
prompt=prompt,
)Execute conversational agent
We will create an instance of the AgentExecutor class, which is responsible for executing the conversational agent.
agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
agent_chain = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True, memory=st.session_state.memory)Wrapping up
We will include a text input field to prompt user to enter a query. If the user enters a query, the AgentExecutor is used to generate a response to the query. The response is then displayed to the user with st.info function.
We also create a collapsible window to show chat history using st.expander function.

The entire code for the app can be found here!
Here is how the final app will look like!
You can play with it here! All you have to do is to upload your PDF and enter your API key. Have fun chatting with your PDFs! :)
III. Deployment
Now that our app is up and running, we can deploy the app to conveniently share with others. There are many options available, but I personally find deploying the app on Streamlit Cloud very simple. With just a few clicks, you can deploy the app and others can access the app using generated link.
The code shown throughout this article is available in this github repo!